
AI enhanced monitoring - Grafana and CrewAI
Monitoring systems have come a long way in helping teams keep an eye on infrastructure. Tools like Prometheus, Grafana, and Alertmanager do a great job of showing metrics, triggering alerts, and providing dashboards. But in many cases, alerts only tell us that something is wrong—not why it happened or what to do next.
To explore how AI could fill this gap, I built a small proof-of-concept that integrates Prometheus, Alertmanager, Grafana, and CrewAI. The idea: connect the traditional monitoring flow to AI agents that can help make sense of alerts in a more useful way and perform actions based on the alerts.
Project Overview
The prototype simulates the following flow. It’s a barebones setup, but it shows how AI can be woven into existing monitoring pipelines without replacing the tools teams already rely on.
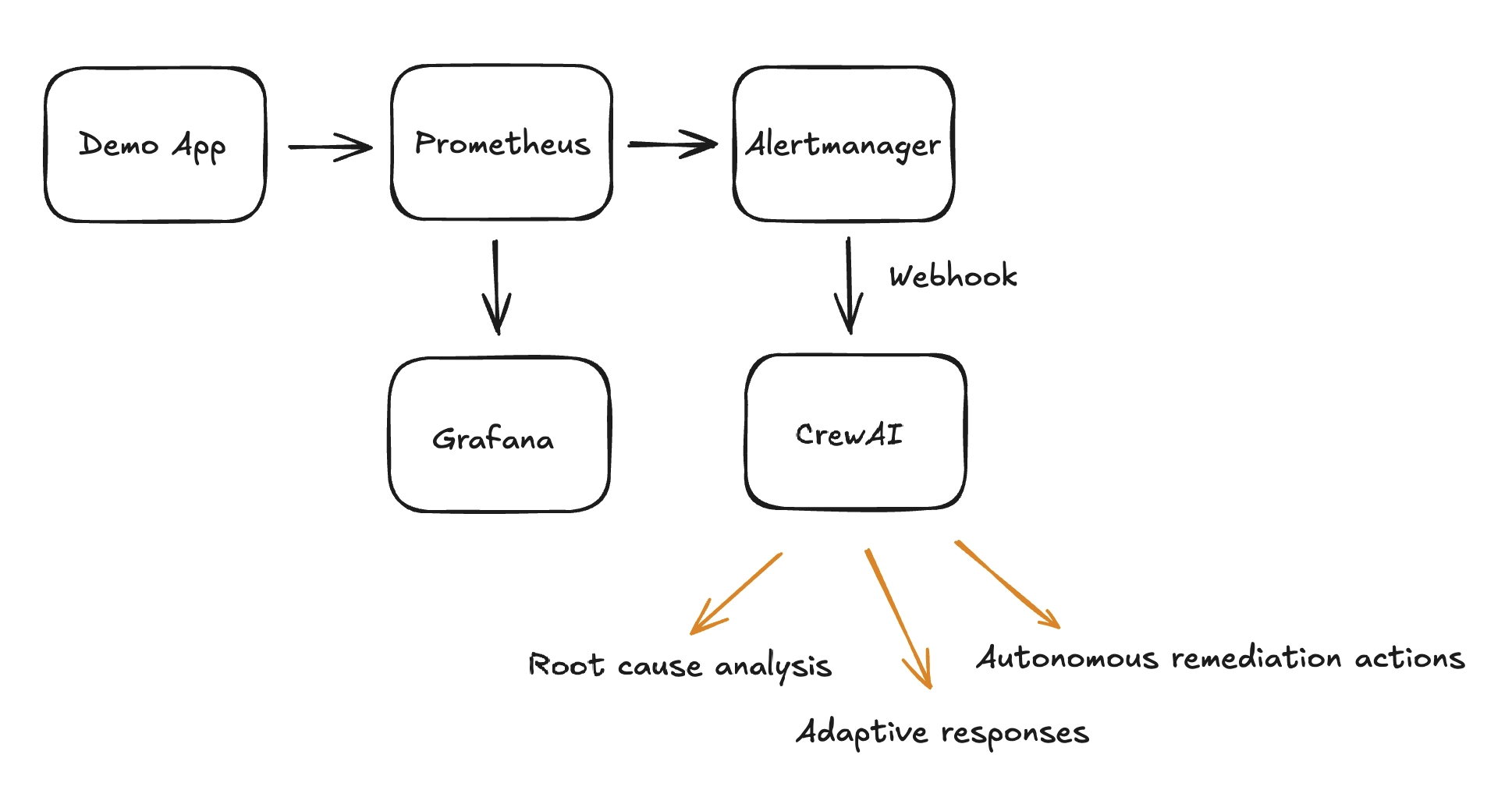
Why It Matters
Prometheus and Grafana are great at:
- Collecting and visualizing metrics
- Sending alerts when thresholds are breached
- Providing static dashboards and notifications
But they don’t cover things like:
- Correlating an alert with recent deployments or log patterns
- Understanding the potential business impact of downtime
- Suggesting or even carrying out safe remediation steps
- Learning from how similar incidents were resolved in the past
That’s where AI can start to add value. Even small steps—like letting an agent query metrics over time or recall past incident reports—help turn raw alerts into more actionable insights.
The Role of AI Agents
For this experiment, I set up a couple of basic agents inside CrewAI:
- Alert Analyzer – looks at alerts and tries to add context (severity, possible causes, recommended next steps).
- Incident Responder – produces a simple report of what happened and what actions could be considered.
This could be extended further with agents that check log data, compare incidents against historical patterns, or even carry out safe automated actions such as restarting a service.
What I Learned
Putting this MVP together tought me a few things:
- Integration is key – AI on its own isn’t useful unless it plugs into the workflows people already use.
- Start small – even one or two simple tools (like querying historical metrics) can add meaningful context.
- Business impact matters – the real value isn’t just fixing alerts faster, but reducing the impact downtime has on customers and operations.
Looking Ahead
This is still just an early experiment. There are many ways it could be extended by connecting to log systems, adding predictive analysis or building in safe remediation options using tools. But even in its basic form I believe it highlights how monitoring can shift from reactive notifications to something more proactive and supportive.
If you are interested, here is the github link to Grafana monitoring