
Building a Privacy-First Local RAG
In today’s data-driven world, organizations are caught between two competing needs: leveraging the power of AI to manage massive amounts of scattered information and ensuring that sensitive data never leaves their secure environment. Traditional search methods fall short, often returning raw documents without context or risking data exposure through external cloud services .
With this project I tackles this challenge by building a fully local Retrieval-Augmented Generation (RAG) chat application. It combines local Large Language Models (LLMs) with a local data retrieval pipeline.
Complete Data Sovereignty with Local RAG
This project is a practical demonstration of a complete, self-contained RAG pipeline that enables people to use AI-driven knowledge access without compromising data security or privacy.
Context-Aware and Verifiable Answers: The RAG pipeline retrieves the most relevant information from a local running ChromaDB vector database and provides it as context to the local LLM via Ollama. This ensures responses are precise, contextualized, and include clear citations to their source documents. This all while the data remains locally.
Technical Architecture & Implementation
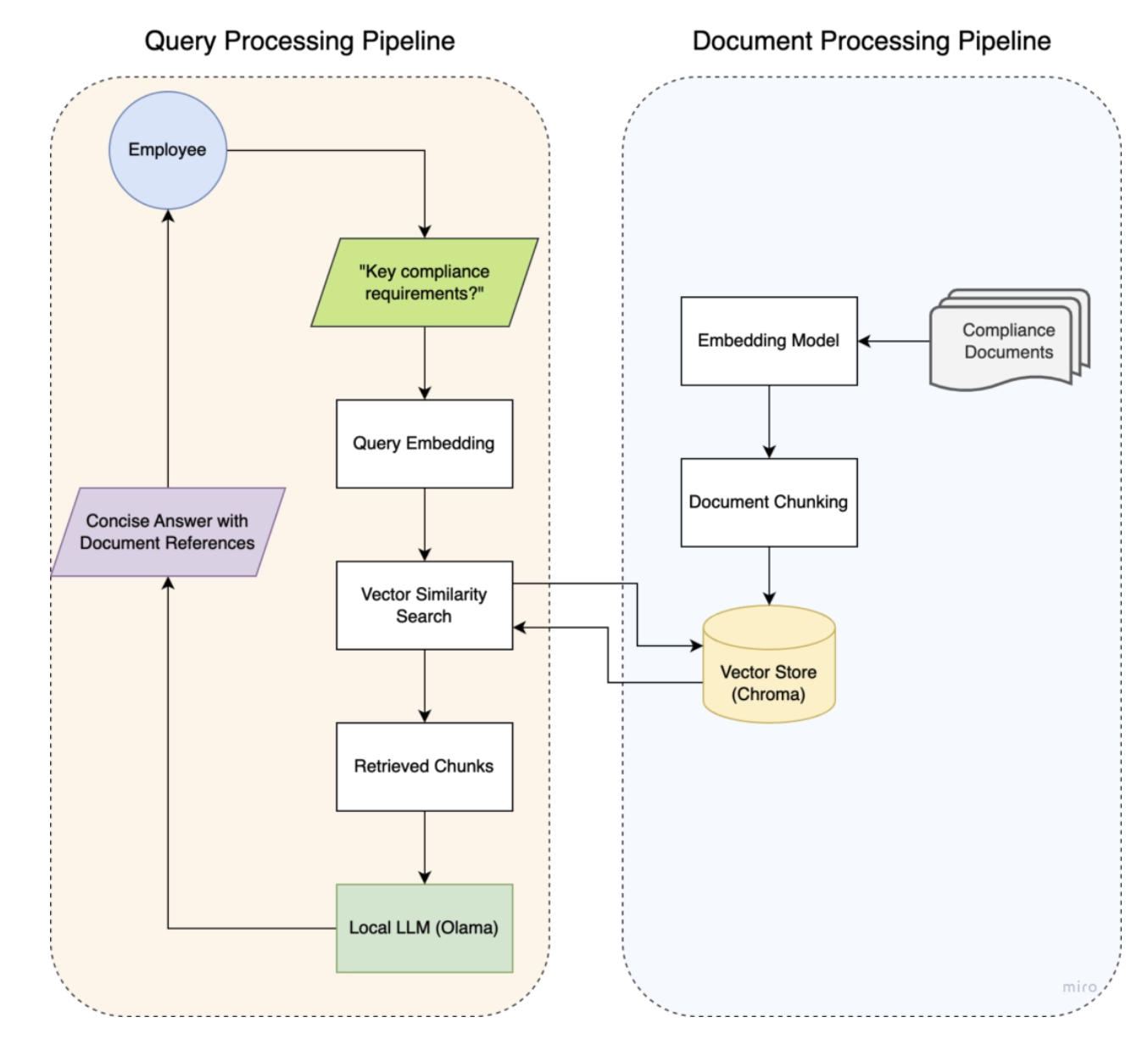
This full-stack application was built with a modern, local-first tech stack.
| Layer | Technology | Implementation Role |
|---|---|---|
| Frontend | React + TypeScript | Interactive chat interface with real-time streaming and source citation display. |
| Backend & API | FastAPI (Python) | High-performance backend serving the RAG workflow and application logic. |
| AI Orchestration | LangChain | Orchestrated the entire RAG pipeline, including document loading, splitting, and retrieval . |
| Vector Database | ChromaDB | Local vector store for fast and efficient similarity search on document embeddings. |
| LLM Runtime | Ollama | Managed and served local LLMs like Mistral and Llama 2 entirely offline . |
| Embedding Models | nomic-embed-text / text-embedding-3-large | Generated vector representations for text chunks. |
The system follows a standard yet powerful RAG pattern, executed entirely on-premises :
- Document Processing: User-provided documents are split into manageable chunks using a RecursiveCharacterTextSplitter for optimal context sizing .
- Vectorization: Text chunks are converted into numerical vectors (embeddings) and stored in the local ChromaDB instance .
- Retrieval & Generation: User queries are embedded and used to find relevant text chunks. These chunks are passed as context to the local LLM, which synthesizes a final, grounded answer .
A Practical use case
Imagine an HR employee needs to find a specific detail in the company’s 100-page policy handbook. Instead of manual browsing:
- They ask in the chat interface, “What is the paternity leave policy for employees in Germany?” .
- The system queries the ChromaDB vector store, retrieving the most relevant passages from the handbook.
- The local LLM generates a concise, easy-to-understand answer, directly citing the sections and page numbers of the source material.
This workflow saves time, drastically improves answer accuracy, and builds institutional trust by making the AI’s reasoning transparent .
Why This Project Matters
- Data Security: The fully local operation is a critical feature if you want to keep your data completely local with exposure to external cloud services.
- Reduced Hallucination: By grounding answers in actual documents, the system mitigates the risk of LLM “hallucination” and allows users to instantly verify the information .
- Operational Flexibility: The modular architecture makes it easy to swap LLM models or add new document types. Running locally also eliminates ongoing API costs .
- Real-World Readiness: The application is a deployable solution for internal workflows like knowledge management, policy lookup, and technical support .
If you are interested, here is the github link to the Local Chat RAG